Automatic sound programming: datasets
·The aim of the Secret Sauce project is to automatically reverse engineer studio sounds, with a focus on guitar effects and synthesizers. Ultimately, we wish to answer the question Wow, how did they make that sound?!
.
This post presents the task and makes the datasets available for whoever would like to try.
Note: for early results, see our follow-up post here!
The Goal
Whether it’s a light echo on a rockabilly guitar, a thick pad on a prog rock record or a heavy sub on a hip hop track, electronic instruments and effects have become a crucial aspect of modern music.
Yet, as many forums and YouTube videos testify, turning ideas into sounds is a difficult craft, which takes years to master. Currently, the method of choice is trial and error, which is often slow and tedious — just ask my neighbors, who will probably never forgive me for the hours I spent trying to sound like the records that I enjoy. Wouldn’t it be great if musicians could simply provide an example of what they want, from a record or real life, and the machines would automatically tune themselves?
The aim of the Secret Sauce project is to do just that. We are developing statistical models to reverse-engineer guitar and synthesizer sounds: give the model a reference sound, and it will tell you how to reproduce it.
A major obstacle is the lack of training data. Music producers rarely give away their presets, which explains the name of our project. And even if they did, separating the sounds that interest us from the others is known to be a difficult task. More convenient sample banks do exist, but few, if any, are labeled.
Our approach is to generate samples from scratch. Thanks to MIDI, many music devices can communicate with computers. Therefore, it is possible to generate and record thousands of random sounds automatically, though this comes at the cost of a bit of a engineering.
We are releasing five collections of sounds created with this method. We recorded a (simulated) guitar with 5 effects, a subtractive synth plug-in and a Moog Sub Phatty. For each instrument, we provide up to 10,000 sound samples, each based on the same note, as well as the settings that we used to produce them. We hope that those datasets will inspire researchers and musicians as much they inspired us!
Datasets
For each dataset, we chose one note (C3), one instrument and one set of parameters. To generate the sounds, we assigned random values to the parameters, sent them through MIDI and recorded the note for a bit less than a second. The code to generate the tracks and clean the data is available on Github, it relies heavily on mido, a great MIDI library for Python.
Guitar Effects
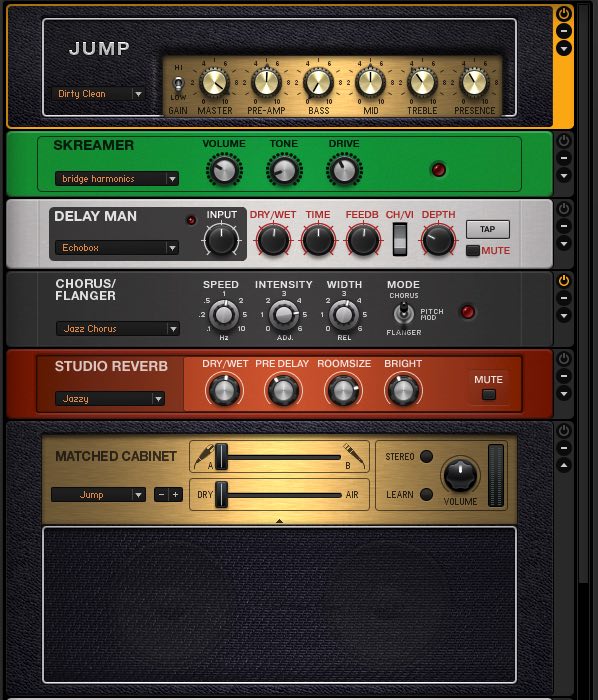 The Guitar Effect dataset is based on a guitar simulator (Ableton Tension) routed to an amp simulator, a distortion, a delay, a chorus/flanger and a reverb. All the effects come from Guitar Rig 5 Player edition, which is free.
The Guitar Effect dataset is based on a guitar simulator (Ableton Tension) routed to an amp simulator, a distortion, a delay, a chorus/flanger and a reverb. All the effects come from Guitar Rig 5 Player edition, which is free.
The dataset comes in two flavors. The tiny version contains 32 sounds which correspond to every subset of effects (5 binary variables). The full version contains 10,000 samples; we varied both the effects (5 binary variables) and their settings (14 continuous variables).
Downloads: Tiny version - Full version
TAL-NoiseMaker
 The Noisemaker dataset is based on TAL’s free plugin, which emulates a substractive synthesizer with two oscillators, a sub, two LFOs and separate envelopes for the filter and the amp.
The Noisemaker dataset is based on TAL’s free plugin, which emulates a substractive synthesizer with two oscillators, a sub, two LFOs and separate envelopes for the filter and the amp.
The light version contains 1,000 samples,for which we varied 1 switch and 4 knobs. The full version contains 10,000 samples, we varied 3 switches and 13 knobs.
Downloads : Light version - Full version
Moog Sub Phatty
 The dataset is based on a Moog Sub Phatty, an analog synth with two oscillators and a sub, and a very aggressive sound. In contrast to the Noisemaker dataset, we varied almost every possible parameter on the front panel, leading to extreme (and sometimes silent) sounds.
The dataset is based on a Moog Sub Phatty, an analog synth with two oscillators and a sub, and a very aggressive sound. In contrast to the Noisemaker dataset, we varied almost every possible parameter on the front panel, leading to extreme (and sometimes silent) sounds.
The dataset contains 10,000 samples, obtained by tweaking 24 knobs and 5 switches.
Downloads: Full version
Details
We sampled the parameter values uniformly over their entire domain (0-127 or 0-16383 based on MIDI specs) and rescale them to the range 0-10.
The samples last between 840ms and 900ms, they are mono encoded in 16 bits/22,050Hz. We did not normalize the volume, but we did use a limiter to avoid saturation. For more information, see the README files in the archives.
What’s next?
For now, our objective is to go through the tasks with various machine learning techniques. We already obtained a few results, described in our follow-up blog post. How close are we to a solution? The video below lets you judge by yourself. We play sounds #8000 to #8015 of the Noisemaker dataset twice. First, we use the original settings. Then, we use settings predicted by a recurrent neural net.
Close, but not quite there! More info in the post.
The next step is to vary the melodic patterns. Currently, we always play the same note, which greatly simplifies the problem. But what happens when we start playing melodies and chords? I suspect that we will need bigger datasets to learn robust representations.
Finally, in the long term, we can imagine reversing the process, and infer sounds from the settings in the spirit of Nsynth, or, perhaps, learn to imitate effects as a style transfer task.
References
The Secret Sauce project is in the lineage of Yee King’s pioneering thesis (2011), which showed that it was possible to program substractive and additive synthesizers with feed-forward nets and genetic algorithms to imitate sounds. We hope to reproduce those results, generalize them to other settings and try many other models. Yee King’s Website is here, and his code here.
If you know any other relevant reference, please reach out!
License
Secret Sauce guitar, virtual synth and physical synth datasets by Thibault Sellam, CC BY 4.0
Acknowledgements
Many thanks to Léo Sellam for the synthesizer, the recording, the advise and the food. I also thank Adrien Durand for his insights, Jaan Altosaar and Eugene Wu for their feedback and the WuLab for the support.